Vanishing Gradients

Super passionate up and coming data scientist documenting my journey! I dedicate my time to learning and creating ML content (data science projects and blog posts).
Why?
Deep learning is massive right now and there are few innovations which really made this possible. Residual blocks are a quintessential modern discovery to solve the problem of exploding and vanishing gradients!
More layers == Better
Modern deep learning revolves around adding more layers, however, this begs the question, at what point will our model no longer improve? Residual blocks provide one way to increase the number of useful layers a neural network may have (before it overfits).
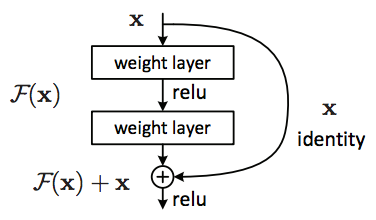
Linking forwards
Residual blocks work by linking the current layer to not only the next layer (like normal) but two or three after it. This allows larger gradients to flow back downstream! By doing so we offset the major impact of vanishing gradients, allowing us to delve deeper once again.
The image was sourced here




