

Why?
Majority of the tutorials I've seen on artificial neural networks focus solely on either the applications or maths behind them, majority of the time completely forgetting about the why and intuition behind this technology. Thus, here I aim to go through both how artificial neural network work, and where they work, explaining them at a more basic level, so anyone can (hopefully) understand.
A breakdown
Part 1: The Point of Neural Networks
Despite simple ways to model any one situation existing through means like linear regression, in the real world, data is often far more complex than a straight line or parable (and often lacks structure). Thus, we can use neural networks when we need to model complex situations like handwriting recognition.
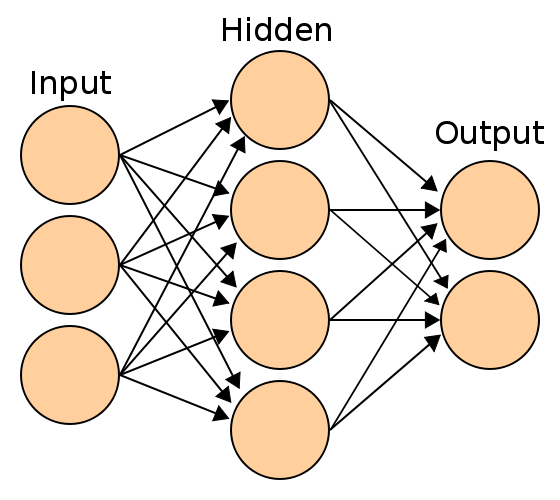
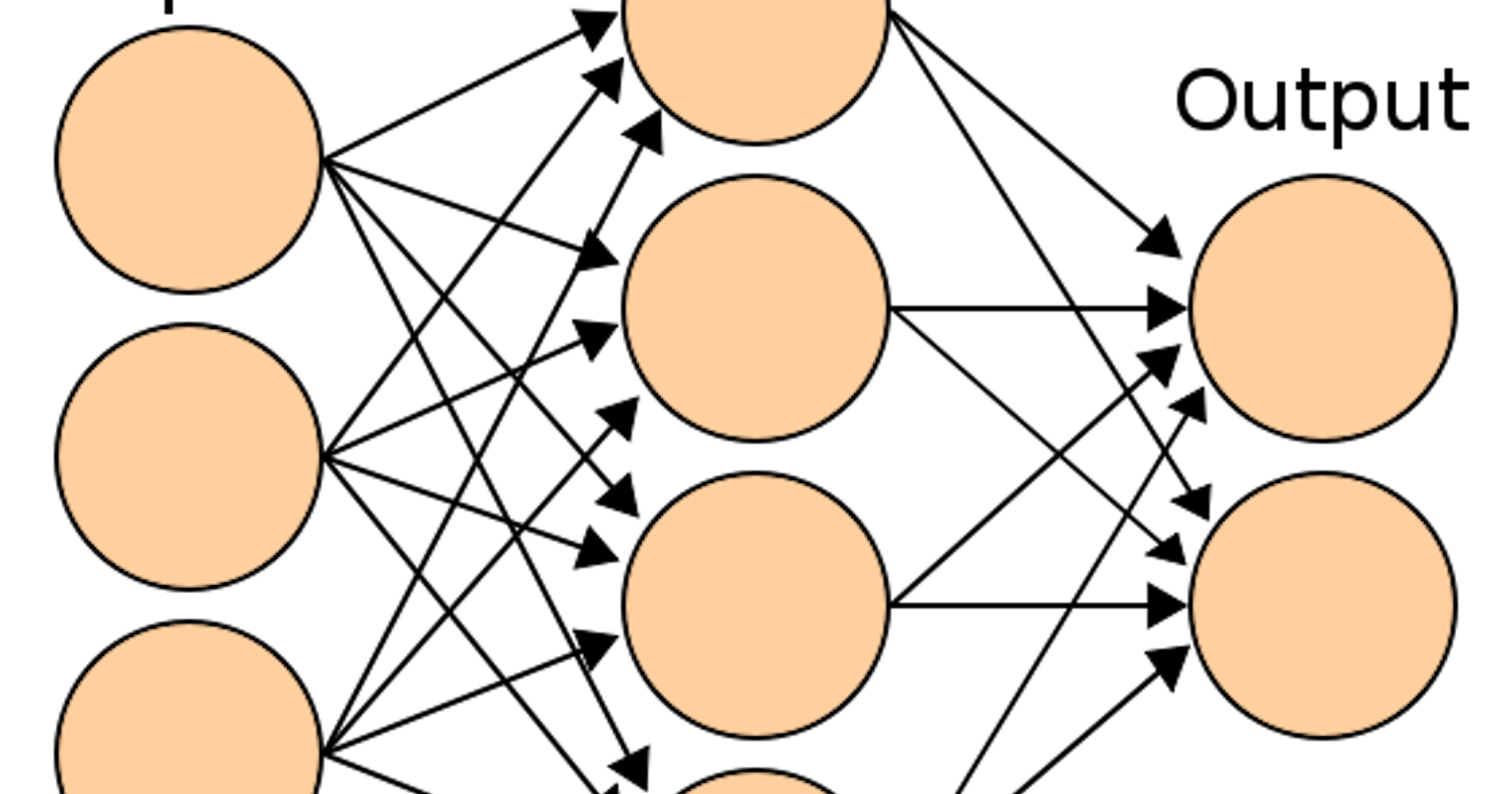
A neural network is split into input, hidden and output layers, where each layer is a group of neurons. The image was sourced here.
Although this diagram may initially appear slightly threatening, it's actually quite basic. It exemplifies how a network may be visually deconstructed into different layers (like separate parts of a problem).
One important thing to note here (that this diagram doesn't explicitly state) is that the connections between neurons (also called nodes) all have associated weights/biases. Weights are just fancy terms for coefficients expressing the significance of each input, and bias' are set terms which sway outputs by a set amount (typically +1).
Part 2: Logical Regression Tying it all Together
In the last section, we discovered that any single neuron can take any number of inputs. So, if we take some n inputs, how do we tie them together to produce the required output? The simple answer to this question is to "scale" our input by our weights (multiplying) and then to finish by adding biases.
Now, all we need to do is compute the output through our activation (hypothesis) function (normally ReLU). Note that this happens identically to linear regression (but now to ALL inputs)
Part 3: Forwards Propagation
If we can already find a neuron's output, why do we need to do anything else? Well, there are two flaws to what I've talked about so far, firstly we've assumed that we are given weights, and secondly, we don't just have a single layer. So, let us consider randomly assign weights to every connection. To address having any number of layers, we use our initial inputs to compute the output of every neuron in the first layer. We can then use them to compute the respective outputs of the neurons in the next layer. This is a recursive process, where we propagate forwards through the network until a final output is generated.
Part 4: Backwards Propagation
Until now I've made an assumption that we already had the weights figured out. That through randomly assigning them we'd be lucky enough to get them all near-optimal. However, for obvious reason's that doesn't exactly happen very often. Go figure.
So how exactly do we find them? The answer is like this: we take a guess, and then incrementally improve it across the network.
We go from the ends of the network (output neurons), finding the cost each weight has on the final output. The cost is used to adjust the weights proportionally (nudging them up/down) to give neuron's which should have fired a greater chance of firing next time. We then recursively repeat this process through the hole network, moving or propagating backwards, to eventual minimize the errors our network makes.
In reality, a modified process called stochastic gradient descent (SGD) is used where we decompose the network several times, once per training example, and then average the adjustments to our weights to give us a final set of modified weights which are more accurate, and so useful in providing the desired outputs.
This is easier to comprehend through a simple analogy where you as an amateur golf player (like me) miss the hole in the ground. When you miss you have to retry your shot, now considering how far the ball either stopped prematurely or passed over the target. By propagated backwards in this way you can use whether or not the ball passed over the target to indicate whether to increase/decrease your strength, and the balls distance from its target to determined approximately how much harder to hit next time. This method takes rubbish random guesses, and slowly improves it, using a weight (utilized strength) to modify your cost function (the success/failure metric of how far the ball is from the hole). However, trying once may not be enough, so you may need to repeat this process many times, and then finally average the effect each incremental adjustment should have had on the weights.
The Nitty Gritty Math Details?
The hardest part of how artificial neural networks work is likely the maths. I would love to go through how this works here, however, I'm still new to this and the maths is something which is explained extensively in other places. The brilliant.org wiki page on this is quite extensive (and well explained). For a shorter/more visual explanation make sure to check out the 3 Blue 1 Brown Deep Learning.
However, what I will do here is compile a rough outline of the alternative terminologies I've seen on this topic. Hopefully, this can clear up any confusion when encountering new sources of information on machine/deep learning.
the desired output (real provided final value)
: the activation (produced value) of the neuron
in layer
(in simpler models this was
)
: the cost/error for training example 0
: the weight at layer
: the bias at layer
: the weighted sum (including the bias) of * values for layer
Note that the
term above can either represent the activation function (output) itself, or the weighted sum for anyone layer (depending on your information source).
THANKS FOR READING!
Now that you've heard me ramble, I'd like to thank you for taking the time to read through my blog (or skipping to the end).